Action - Speech Output
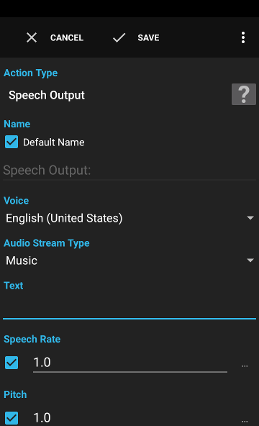
The action Speech Output uses the default text to speech engine installed to read the defined text.
Examples:
- Read out the incoming SMS.
- Read the current time when you press a shortcut.
Settings
Voice
The voice/language to use. The list of available voices depends on the installed TTS engine.
Audio Stream Type
The type of the audio stream to use to emit the speech output.
Text
The text to speak. Variables are supported.
Examples:
Examples:
- use
{triggertime,to read the timedateformat, HH:mm:ss}
Speech Rate
Whether or not to use a custom speech rate (0.5=slow, 1.0=normal, 2.0=fast). Not supported by all text to speech engines. Variables are supported.
Pitch
Whether or not to use a custom pitch (0.5=low, 1.0=normal, 2.0=high). Not supported by all text to speech engines. Variables are supported.
Synthesis Embedded
When checked the engine must not use network access to synthesise the speech. Not supported by all text to speech engines.
Synthesis Network
When checked the engine must use network based synthesis. Not supported by all text to speech engines.
Show status bar notification to stop speaking
Shows a status bar notification when the tts engine is speaking that stops the speaking when selected.
Request audio focus
Defines whether or not and how Automagic should request audio focus. This causes other apps like music players to pause playback or to temporarily lower the volume.
Possible settings:
Possible settings:
- Transient: Automagic requests temporary audio focus, other apps usually pause playback temporarily (depends on app)
- Transient may duck: Automagic requests temporary audio focus, other apps either temporarily pause playback or temporarily lower the volume (depends on app)
- Normal: Automagic requests the normal audio focus, other apps usually pause/stop playback (depends on app)